


Setting up Fiddler for Webresources
27. März 2024
Using C# in Power Automate Flows
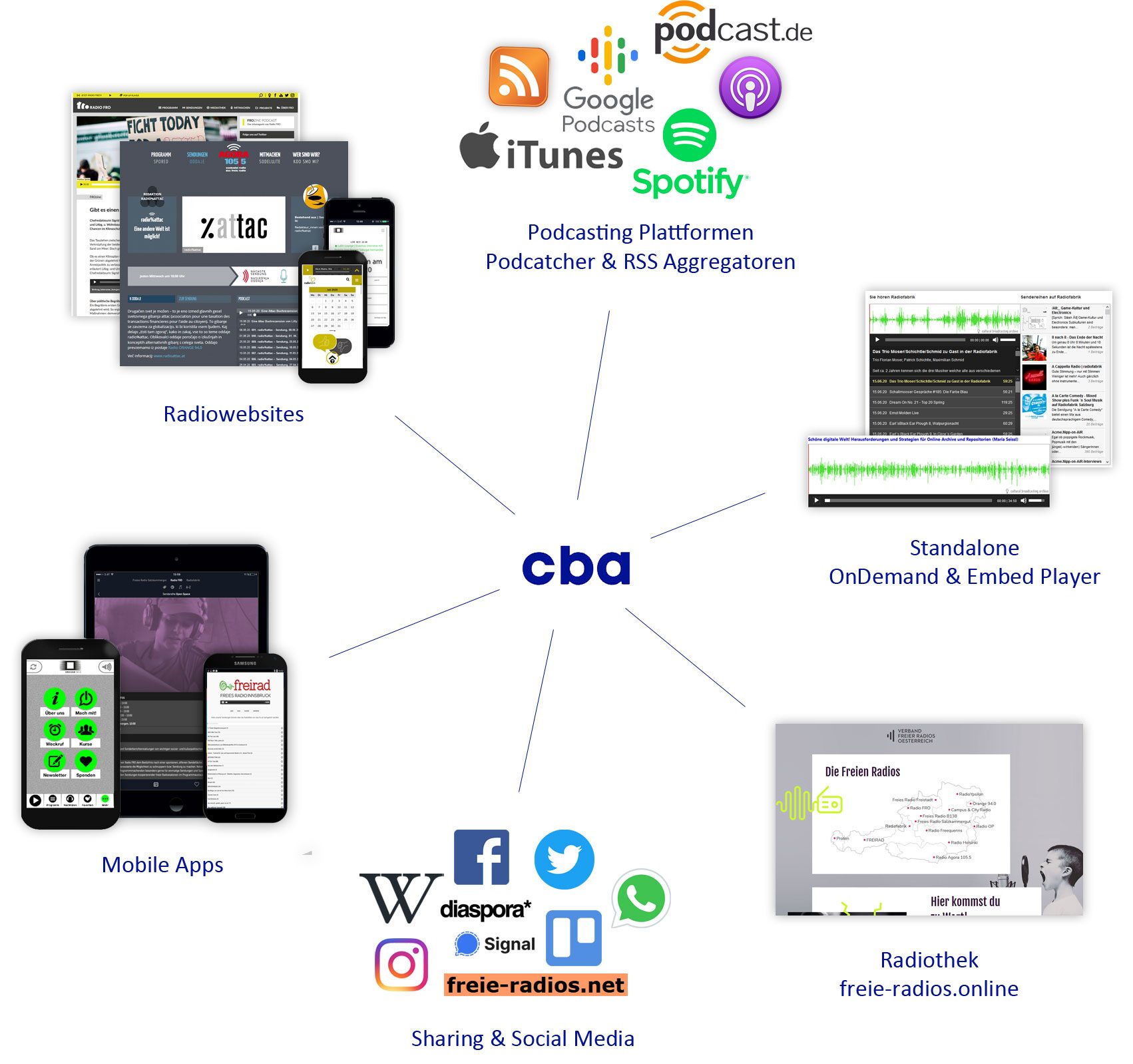
19. November 2024repco (replicator + collector) ist ein Open Source Metadaten-Aggregator, der für das CBA (Cultural Broadcasting Archive) weiterentwickelt wurde. Die Umsetzung wird im Rahmen eines Projektes zur Demokratisierung von Social Media Plattformen von der Europäischen Union gefördert.
Repco soll verschiedenste Blogs, Feeds, Radiosender und andere Endpunkte von Podcasts, Videos, Musik und Blogposts einlesen, deren Metadaten sammeln, kategorisieren und aufbereiten. Diese Daten werden über eine GraphQL Schnittstelle bereitgestellt und können dann, z.B. von Webseiten, konsumiert werden.
Eine Herausforderung bei diesem Projekt stellt die Menge an Daten dar: über 50 verschiedene Datenquellen mit gesamt fast 250.000 Beiträgen in bis zu 15 Sprachen müssen in regelmäßigen Abständen eingelesen und aufbereitet werden.
Über das Cultural Broadcasting Archive
Das Cultural Broadcasting Archive ist eine zivilgesellschaftliche Medien- und Kommunikationsplattform. Wir betreiben eine gemeinnützige und unabhängige technische Infrastruktur abseits kommerzieller Interessen. Damit fördern wir freie Meinungsäußerung, Medienvielfalt und digitale Kommunikation. Das ist unser Beitrag zur Demokratisierung der digitalen Medienlandschaft.
Das CBA ist Österreichs größter Podcastprovider mit völlig freiem Zugang. Es stehen über 140.000 Audiobeiträge in rund 50 Sprachen aus einem breiten Themenspektrum zum Anhören und zum Download zur Verfügung: Von Podcasts ethnischer Minderheiten über Politik und Medien bis hin zu Musik, Literatur, Wissenschaft, Kultur oder Philosophie. Die Plattform verhilft Special Interest Programmen zu einer größeren Öffentlichkeit und ermöglicht die Kommunikation zwischen Produzent*innen und Rezipient*innen.
Das CBA ist ein Archiv des gesellschaftlichen, politischen und kulturellen Geschehens einzelner Regionen Österreichs und Deutschlands und hat sich seit seiner Gründung im Jahre 2000 zu einem bedeutenden Zeitdokument mit starkem Lokalbezug entwickelt. Das Archiv steht neben dem privaten Gebrauch insbesondere für Bildungsarbeit und für Recherchezwecke offen. Die Plattform wird daher beispielsweise in Schulbüchern als Recherchequelle empfohlen (z.B. „Durchblick 3“ für Geografie- und Wirtschaftskunde, Westermann Wien).
Technische Weiterentwicklung von repco
Als Grundlage für die gewünschten Weiterentwicklungen diente ein bestehender Prototyp, dessen Funktionalität, unter anderem, um folgende Features erweitert wurde:
- Mehrsprachige Metadaten
- Volltextsuche
- zusätzliche Arten von Import-Datenquellen
Volltextsuche
Ein der Aufgabenstellungen war es, Konsumenten der repco-Metadaten eine Volltextsuche über bestimmte Metadaten zu ermöglichen.
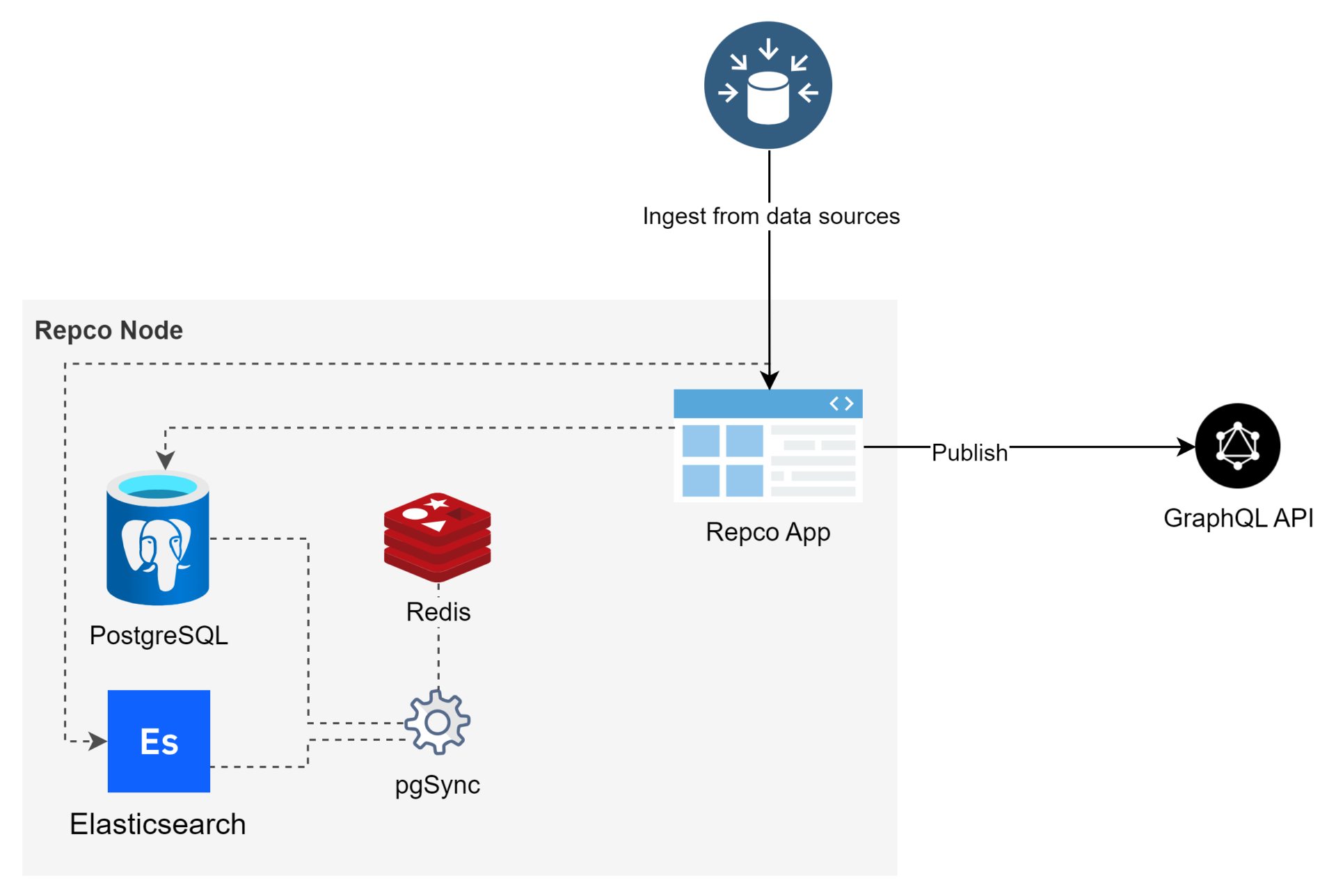
Unsere Integration von elasticsearch in Kombination mit pgSync ermöglicht umfangreiche Volltext-Suchmöglichkeiten. Durch die Verwendung von pgSync erreichen wir eine automatische Synchronisierung von definierten Metadaten im Such-Index bei jeder Aktualisierung („Ingest„) der Datenquellen in repco.
repco stellt den Anwendern („Konsumenten“) eine automatisch generierte GraphQL API auf Basis von postgraphile zur Verfügung. Um die Volltextsuche in diese API integrieren zu können, haben wir mehrere Plugins entwickelt die spezielle Filterfunktionen abdecken. Eines dieser Plugins ermöglicht es uns, Suchbegriffe in elasticsearch zu suchen und diese dann mit ihren entsprechenden Einträgen in der PostgreSQL Datenbank zu verbinden um die angereicherten Suchergebnisse anschließend in der GraphQL API ausgeben zu können.
Mehrsprachige Metadaten
Inhalte in allen verfügbaren Sprachen sammeln ohne die Such-Performance und die Qualität der Suchergebnisse zu beeinträchtigen ist eine komplexe technische Aufgabenstellung.
Die Volltextsuche ist eine der wichtigsten Komponenten von repco, damit Usern relevante Suchergebnisse im stetig wachsenden Archiv angezeigt werden können.
Während der Umsetzungsdauer haben wir verschiedene Lösungsansätze evaluiert und hinsichtlich ihrer Auswirkungen auf die Performance analysiert.
Schlussendlich konnten wir die Anforderung durch die Verwendung von PostgreSQL-nativen JSON Columns lösen. Diese bieten einen guten Kompromiss zwischen Flexibilität und Performance, sowie durch die Verwendung von JSON Functions gute Filtermöglichkeiten.
Neuer Endpoint Ingestor
Die verschiedenen Daten-Endpoints von repco inkludieren zum Beispiel RSS-Feeds oder die WordPress API des CBA.
Im Laufe der Entwicklung wurde es notwendig, weitere Metadaten einer spezifischen API periodisch abzufragen.
Da repco bereits umfangreiche Möglichkeiten bereitstellt Daten einzulesen und aufzubereiten, haben wir die Anbindung der API über die bestehende Ingestion-Architektur umgesetzt. Dazu entwickelten wir einen neuen Endpoint Ingestor, der es ermöglicht repco mit dieser Web API zu verbinden.
Resultat
Durch unsere agile und nachhaltige Arbeitsweise konnten wir für das CBA großen Mehrwert unter berücksichtigung der gegebenen Budget- und Zeitgrenzen generieren. Unsere Expertise in einem breiten Technologie-Stack hat es uns erlaubt den bestehenden Prototypen nahtlos zu übernehmen und sinnvoll auf die bestehende Basis aufzubauen.
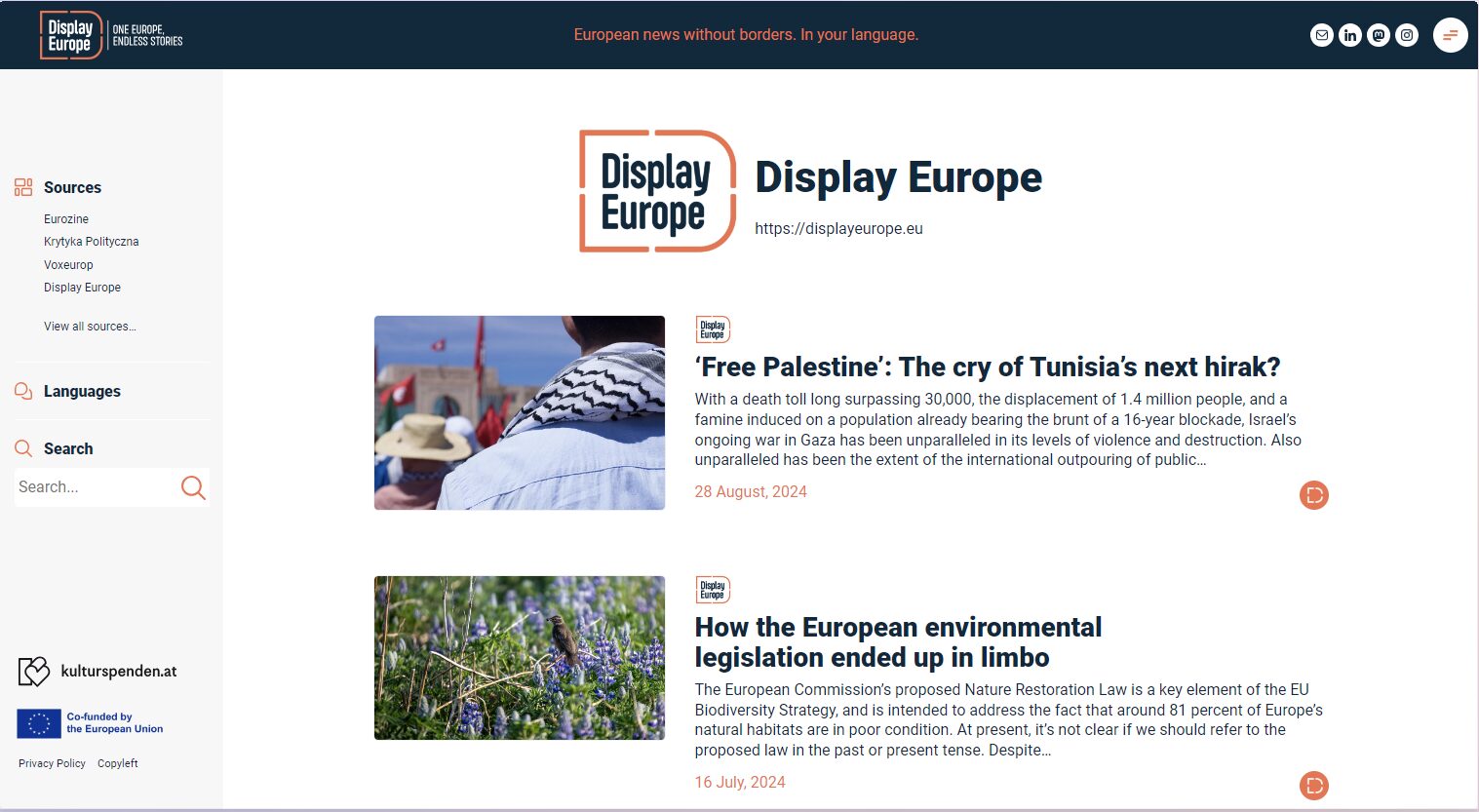
Der von Repco bereitgestellte Datenfeed wird bereits auf mehreren Webseiten genutzt, wie zum Beispiel die Plattform displayeurope.eu zeigt: Dort wird der Beitrags-Feed anhand von Daten aus repco gefüllt und gebündelt präsentiert. x
Gerne erteilen wir Ihnen weitere Auskünfte zu diesem spannenden Projekt auf Anfrage.
Haben Sie ein Projekt, das von unserer Expertise profitieren könnte? Unsere Digitalisierungsexperten können Sie punktuell unterstützen oder auch die gesamte Projektumsetzung für Sie übernehmen. Kontaktieren Sie uns für eine kostenlose Erstberatung.


{kind=link}